
SQL for programmers – indexes are not magic
Using SQL is preferable or even necessary. It’s good to know how the system works to do it right. Learn SQL, and you will not need to call for help.
Using SQL is preferable or even necessary. It’s good to know how the system works to do it right. Learn SQL, and you will not need to call for help.
I can remember the time when the Internet was buzzing with discussions on using ORMs over stored procedures. And you could see arguments against dynamic SQL queries almost everywhere. At that time, most of the apps were susceptible to SQL injection attacks. Some older PHP users might even remember mysql_escape_string and mysql_real_escape_string functions.
The world is changing, though, and ORMs have become the standard. Now, when the interns hear about database using stored procedures, they weep. For them, it’s like hearing they have to write web pages optimized for IE5.
We know the arguments against ORMs well. They worsen the performance and hide both the complexity and capabilities of the database. Finally, they introduce cost-generating dependencies to the project. While it is hard to disagree with these arguments, I fail to see how they could translate into the reality of software development. It is rare for ORM overhead to become a problem, and the app development becomes much simpler.
Unfortunately, ORMs are not omnipotent. Using pure SQL is often preferable or even necessary. And to do it right, it’s good to know how the system works.
tl;dr: Learn SQL, so you will not need to call for help.
Many people naively think that their relational database stores data like a spreadsheet, a list of cells and columns arranged on the disk. For them, indexes are like magical creatures that speed the data access up.
Imagine we create a table with the query as follows:
CREATE TABLE People(
ID INT PRIMARY KEY NOT NULL, -- some kind of autoincrement here – depends on your database
Name VARCHAR(128) NOT NULL,
BirthYear INT
)
We fill it with data:
| ID | Name | BirthYear |
|---|---|---|
| 1 | Alice | 1987 |
| 2 | Eve | 1984 |
| 3 | Bob | 2002 |
| 4 | Charlie | 1993 |
Next, we create index on BirthYear column:
CREATE INDEX IX_People_BirthYear ON People(BirthYear)How will our index look?
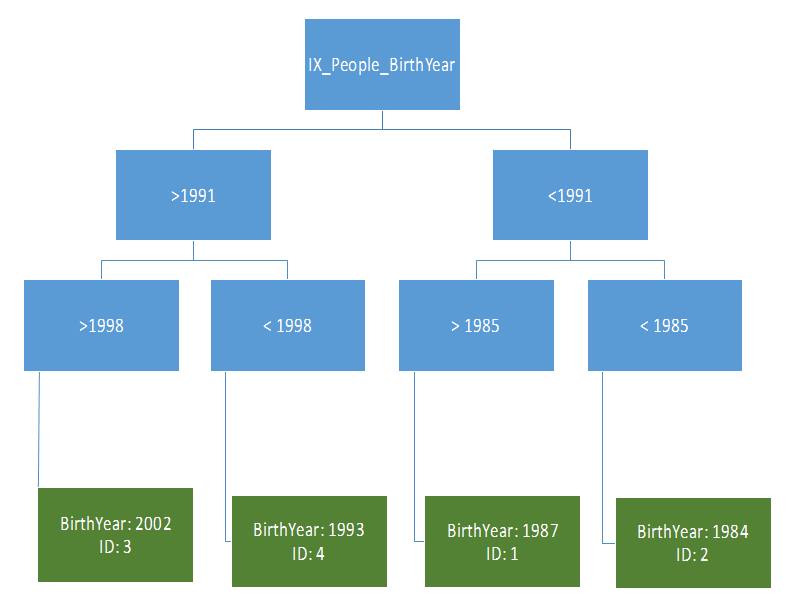
The structure of a typical database index is a B-tree, a generalization of a binary tree with elements that could have more than two leaf nodes.
Databases can make further optimizations (eg. multiple nodes stored in a single block on the disk, leaf nodes with pointers to the following leaf nodes), but we will not dwell on those here.
The expected data access time complexity of B-tree is O(log n), contrary to O(n) of the table scan.
Modern databases support indexes created on multiple columns. In such indexes data is sorted by several keys.
CREATE INDEX IX_People_BirthYearName ON People(BirthYear, Name);
In this index, data will be sorted first by year, and then by name. Here are some examples of the queries that can take advantage of an index like this:
SELECT BirthYear, Name, ID FROM People WHERE BirthYear > 1995
SELECT Name, COUNT(1) FROM People WHERE BirthYear > 2000 AND Name LIKE ‘A%’
GROUP BY Name
SELECT Name FROM People WHERE BirthYear > 2000 OR BirthYear < 1980
What do those queries have in common? They all refer to BirthYear, so query optimizer sees it can use the index to swiftly find desired records. Looking for both name and year at the same time, we can narrow down our search to an even smaller fragment of the index.
If we look at the same time and the name and the year, the search can be narrowed down to an even smaller portion of the index.
But if we wrote a query like this:
SELECT Name FROM Peopleor
SELECT Name FROM People WHERE Name = ‘Alice’our index would be useless since the data is sorted by birth year. Searching in the index would take as much time as searching in the table.
Unfortunately, everything has a price. Indexes speed up searching in the table, but executing UPDATE, INSERT or DELETE statements require updating data in the index. Average index update cost is O(log n). Further problems are caused by the fact that a typical index tree is not self-balancing. It means multiple data modifying operations cause worsening of the data access time with the worst case being a linked list. When that happens, index rebuilding is necessary – it’s the costly operation of balancing tree and wiping garbage (deleted records).
Various databases limit simple indexing of strings as well. An example of this is allowing only limited length fields to be indexed, or indexing only the first n characters. You can’t naively index certain types, such as XML, JSON, or BLOBs, but it’s possible to index them by eg. XQuery expression.
Indexes are necessary for any SQL backend application to achieve satisfying performance. Understanding the underlying data structures is necessary to write performant queries and to use abstractions over SQL efficiently.
In my next article, we will dig into common database design issues, such as user-defined fields, improper usage of data types and unnecessary over-normalization.
 Hi, I’m Marcin, COO of Applandeo
Hi, I’m Marcin, COO of Applandeo
Are you looking for a tech partner? Searching for a new job? Or do you simply have any feedback that you'd like to share with our team? Whatever brings you to us, we'll do our best to help you. Don't hesitate and drop us a message!
Drop a message