Home / Blog / Does AI Cost You a Fortune? Learn the Best Cost-Cutting Tricks!
Does AI Cost You a Fortune? Learn the Best Cost-Cutting Tricks!
AI costs are huge. Many business leaders and app developers are looking for ways to reduce AI costs. Others wonder what those prices consist of. Some simply want some ready-made solutions and a list of what works best. In this article, we catered to all of them. Read it now and start reducing those costs and use AI in a smarter way.
AI is an enormously powerful tool, currently transforming industries worldwide and it’s marching onward ever faster, taking industry after industry. AI cost is growing higher by the day, too.
As businesses adapt to AI, including generative AI, the cost of implementation, development process and maintenance is often overlooked or outright too concerning for them.
The actual AI cost can be worryingly high. Whether you’ve already got AI in your own business operations or are just looking to jumpstart processes automation, you have to deal with the range of expenses involved in an AI project, such as development, hardware, software, data acquisition, personnel, and ongoing maintenance, head on.
We’ll sort this out for you.
Defining Software Development AI Cost
Have you already taken the plunge with AI? You now know the costs of machine learning can spiral out of control and eat into budgets and the bottom line. Still haven’t? You must be wondering how to make AI a more cost effective solution that fits with your business goals.
The cost factors vary widely depending on the scope, functionality, and whether the development is done in-house or by a development team of external experts. The development, enhancement, and maintenance costs of AI solutions are influenced by the specificity of AI features, the type of AI (custom vs. off-the-shelf), and other factors. Some of us simply don’t know why this or that AI-thingy costs what it costs. What do these prices consist of? What is it that affects their change?
In this article we’ll drill down into the real costs of AI software and AI development costs. You’ll also get a ready-made set of the best practical, proven tips to help you reduce those costs without losing much.
The proof of the pudding is in the eating. You’ll have a taste of our AI projects and summarization task. Having seen the results firsthand, you’ll come to all the conclusions yourself.
Read on to dive head first into the intricacies of artificial intelligence cost creation and learn how to achieve significantly reduced operational costs of AI. Let’s go!
Understanding Artificial Intelligence Costs: What Do We Pay For?
Generative AI remains a tough nut to crack and quite a head-scratcher for many seasoned people in IT. Even if they already read our handy guide where we did our best to unravel the puzzle of GenAI.
Implementing and maintaining an AI system involves significant costs and considerations, including development, maintenance, training, hardware, and overall AI implementation. Even developers significantly influence the cost of AI development, and there are various options for hiring them. And yet one of the most crucial things to get is tokens, if you want to drive the artificial intelligence cost down.
Tokens have a huge influence on AI models and their pricing. In the context of generative AI and AI technology, a token is simply a unit of text. You can learn more about them here.
Now let’s find out their costs!
Tokens Today: What Are The Costs?
To calculate tokens, use a tool provided by the owner of a particular LLM you choose. Open AI offers a calculator which is easy to use and understand here. Such tools show you how any piece of text might be tokenized by their language model, but also the total number of tokens in that text.
Multiple OpenAI models differ in their capabilities and pricing models. You can check their up-to-date pricing here. They let you view the prices in units of either per 1M or 1K tokens depending of the volume you’re working with, which is very handy. You can think of tokens as pieces of words, where 1,000 tokens is about 750 words.
Do you need help reducing your AI cost as little as possible as fast as possible? Our team of experts is ready to chat and make these AI cost-cutting tricks work for you! Fill in the form below and we will contact you.
Get in touch
AI Cost Reduction: Some AI Cost-Cutting Techniques
Cost reduction practices can be put into three groups:
Tinkering with the prompt.
Deploy the models themselves differently.
Choosing the much cheaper Batch API by OpenAI.
And who are those who make these efforts come to fruition? It’s machine learning engineers, data scientists, and software developers. They are crucial in AI solution development, highlighting the high demand and cost of hiring such specialized talent.
Prompt Optimization & Compression Approach
Shorten the Prompt: Just trim the prompt down as much as you can. The data quality won’t be affected too much, but the development costs will go down. The math is simple: fewer prompts, fewer tokens. Remember, though, that a buzzcut is better that going bald in this case.
Format More and Reduce Output: Be very methodical when creating a prompt. Clearly indicate the smallest yet realistic and feasible length and format of the response. Or simply set a maximum output size. This way the number of tokens used will go down, and so will your costs. Yet beware of making the prompt way too small. There’s a limit to how small of the context you can provide, before output quality goes down way too much.
Choose English Where Possible: Prompts made in the lingua franca of the world cost many fewer tokens than those made in languages like Polish or Chinese, due to tokenization methods.
Merge Queries/Combine Your Requests: Whenever you can, try grouping your requests together instead of sending them individually. The lower the number of requests needed, the lower your overall costs. Combining the requests without the right skills, could potentially significantly decrease the effectiveness. Strike the right balance!
Use LLMLingua: This is a tool which serves as an intermediary between the mountains of raw data we feed LLMs and those models. The amount of data is so overwhelming that it slows down processing and results in poor performance. This is where this tool comes to help. It chops the information down into bite-sized instructions for the model to easily digest and process. You can learn more about it in this highly illuminating article.
Supposing you decided to give LLMLingua a go. What are its upsides and downsides?
PROS
CONS
Cost Reduction through compressing the prompts by up to 20 times
Difficulty Maintaining Prompt Accuracy, as a shorter prompt may fail to capture your original intent
Improved Efficiency, as compressing the input data leads to faster processing times
Added Complexity, as implementing and maintaining such a compression system is tough & has to be properly managed
Lower Computational Costs, as fewer data require fewer hardware work
Worse Performance & Time Delays: you may have to wait to get your response
Pros and Cons of LLMLingua
When it comes to using LLMLingua, the key is finding the right balance—just as in all of the methods above, compression can provide cost and efficiency benefits, but you have to be very thoughtful about how it’s applied. Push too hard and the potential downsides immediately overtake the upsides.
Optimizing the Use of AI Models: Deploying AI Models in a Cost-Effective Manner
Wise Model Selection:
Got a simple task and a very short prompt? Go for an older & cheaper model. It may well be sufficient. Think GPT-3.5.
Got a difficult task and a huge prompt? Think GPT-4o. Or opt for custom AI development altogether.
Remember, though, that custom AI development is costly, time-consuming and sometimes involves building AI from scratch and training it for your specific needs, and business requirements. Integrating bespoke natural language processing into AI development can further increase these costs.
The basic version may be more than enough to lower AI development costs in some cases.
Task Splitting: Approach the problem you’re trying to solve with AI in such a way, so that only some of its smaller subtasks do actually require the use of a custom AI solution.
Choosing Batch API
The Batch API from OpenAI is an option for those who don’t need immediate responses, offering a 50% discount. This is ideal for processing jobs that don’t require quick turnaround. If you’re fine with a 24-hour response time or face rate limits, you can use the Batch API to save on costs.
Case Study: Comparing Small and Large Language Models in a Summarization Task
Let’s see how SLMs and LLMs compare again with our favorite benchmark—yes, we are using it yet again—text summarization. We showed in our previous work that even smaller models can do quite well for some tasks. Before that we went even smaller. But now we want to see how the latest and greatest large language models (LLMs) compare to the smaller ones.
Instead of just showing that LLMs outperform smaller models, we wanted to ask a more nuanced question: is it always worth using the most expensive, highest performing model? To answer this, we’ll compare the summarization results of GPT-3.5 to the newer GPT-4o. Does the older lag behind the newer one? GPT-4 Turbo was skipped because of the discrepancy between the higher costs and the lack of a quality boost.
We used multiple evaluation methods to measure summarization quality: established metrics like ROUGE and BERTScore, and a new one: using LLMs themselves as evaluators. We also looked at some of the summaries with the biggest score changes and our personal, subjective opinions too.
Results are not just in English, we checked across multiple languages as well. So we have a full picture of how these models do summarization in different scenarios for better operational efficiency and cost management.
Different AI algorithms vary in their efficiency and costs. Hiring software developers as part of the AI development team also adds to these costs, given the growing demand for their skills and competitive salaries.
So here’s the summary. We hope you’re as excited as we are right now!
Our Results
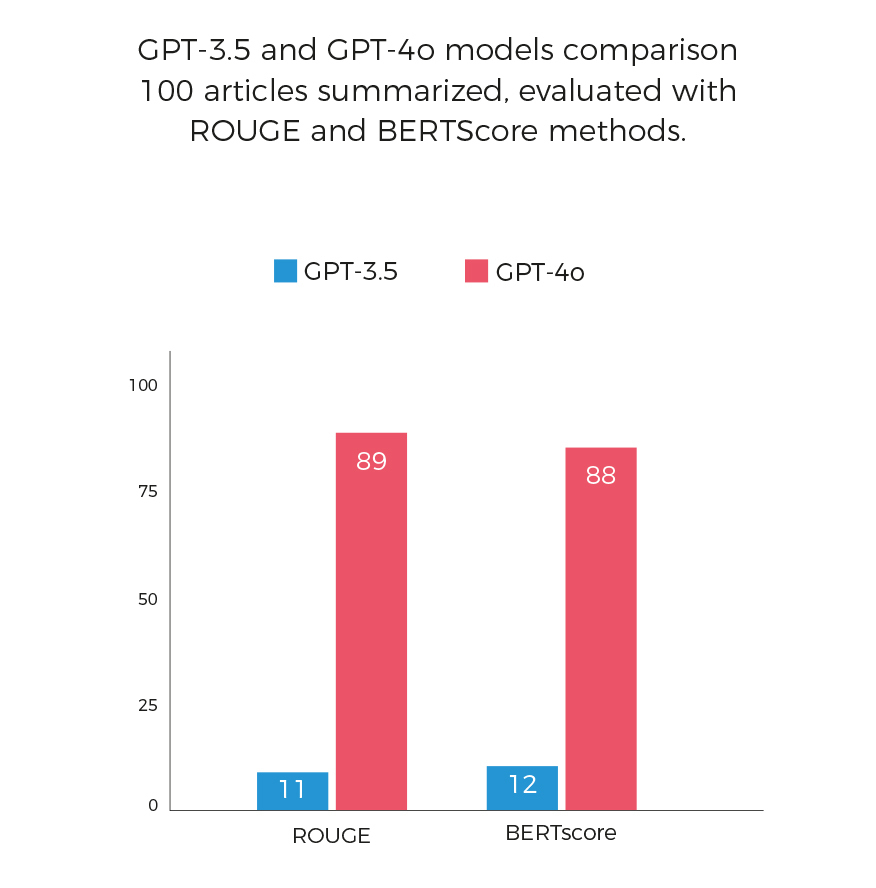
We compared the performance of GPT-3.5 and GPT-4o models by summarizing 100 articles from huggingface and evaluating the summaries using ROUGE and BERTScore metrics. The higher-scoring summaries received a point.
By tallying the points, we assessed whether the more advanced GPT-4o consistently outperformed the older GPT-3. 5 in summarization tasks, or if the more affordable GPT-3.5 can still be effective in certain cases.
GPT-3.5 vs GPT-4o: summarization task
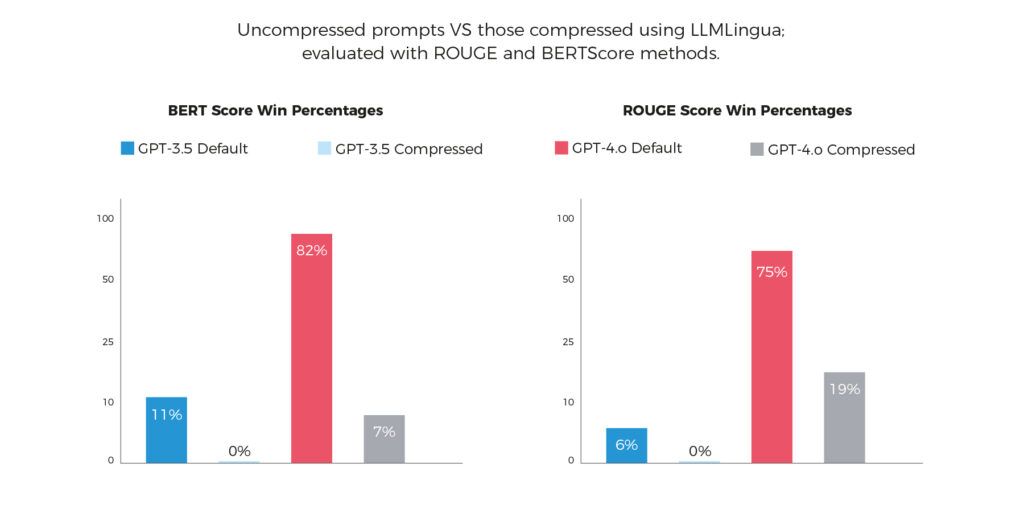
The results quantify the tradeoffs between model performance and cost. We then tested uncompressed prompts against those compressed using LLMLingua, using the same evaluation techniques.
Performance of prompts compressed with LLMLingua
Was It a Success or Not? Our Thoughts
The GPT-4o model outperformed GPT-3.5 in ROUGE and BERTScore evaluations across the articles summarized. The more advanced GPT-4o produced better summaries, as expected.The ROUGE and BERTScore results were quite similar.
Subjectively, the GPT-3.5 model often preserved key information and generated readable, coherent summaries without significant quality differences compared to GPT-4o.
Outcomes also varied by language. For German, BERTScores were lower than English, but model differences were similar. For Chinese, summary quality was poorer overall, and GPT-3.5 lagged significantly behindGPT-4o, with up to 20% score differences. This shows language support has improved in the newer model.
Compressed prompts for GPT-4o sometimes did outperform their uncompressed counterparts. But when we dug a bit deeper, we found that these compressed prompts were still prone to missing critical information. Thus the difference in performance was negated.
There are substantial cost differences between the two models. After our careful analysis, we can recommend using the more affordable GPT-3.5 in most cases. However, this isn’t a universal rule—there will be times when the performance gap is significant enough to justify the higher cost of GPT-4o.
So how in the end should you select? It really comes down to evaluating each specific use case. But take into account the main three factors:
language;
frequency of use;
budgetary constraints.
The final conclusion is that while the GPT-4o model objectively provides better results, GPT-3.5 can be sufficient in many cases. We also found that compressing prompts to save costs can come at the expense of summary quality. Omitting important details is not the expense most of the readers are ready to endure. That’s why it’s crucial to constantly manually review the results, as after data compression some key information may be lost.
Summary: Reducing AI Cost and Maximizing ROI
When using OpenAI models, newer versions like GPT-4o often deliver better results but are more expensive. Balance quality and cost, especially for high-volume applications. Consider using older, more affordable models like GPT-3.5 if they meet your needs.
Optimize prompts by shortening them and reducing output to decrease processed tokens. Techniques like prompt compression with LLMLingua can also help, but require careful configuration to maintain quality.
Choose the right model for each task. In many cases, simpler and more cost-effective solutions can be as effective as advanced, expensive options. Don’t assume the latest model will always provide expected quality improvements if the cost difference is substantial.
Applandeo has the expertise to help you minimize expenses while maintaining high-quality results for your AI integrations.
Are you looking for a tech partner? Searching for a new job? Or do you simply have any feedback that you'd like to share with our team?
Whatever brings you to us, we'll do our best to help you. Don't hesitate and drop us a message!